第二十六节、工作队列
本节用于介绍工作队列
一、工作队列的基础概念
1、什么是工作队列?
工作队列(workqueue)是实现中断下文的机制之一,是一种将工作推后执行的形式。那工作队列和我们之前学的tasklet机制有什么不同呢?tasklet也是实现中断下文的机制。他们俩个最主要的区别是tasklet 不能休眠,而工作队列是可以休眠的。所以,tasklet可以用来处理比较耗时间的事情,而工作队列可以处理非常复杂并且更耗时间的事情。
2、工作队列(workqueue)的工作原理
Linux系统在启动期间会创建内核线程,该线程创建以后就处于sleep状态,然后这个线程会一直去队列里面读,看看有没有任务,如果有就执行,如果没有就休眠。工作队列的实现机制实际上是非常复杂的,初学阶段只需要了解这些基本概念接口。
类比理解:
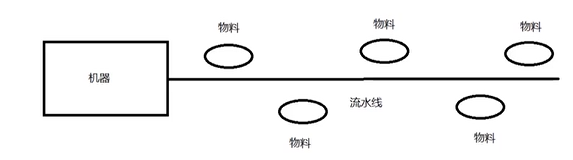
流水线上的机械:Linux系统自动会创建一个。多种不同的物料使用同一个流水线机械,那么这个就是共享工作队列的概念。
如果当前的流水线机械不能满足我们加工的物料,我们是不是就需要重新定制一台流水线机器呢,这个就是自定义工作队列的概念。
共享工作队列有什么有缺点呢?
不需要自己创建,但是如果前面的工作比较耗时间,就会影响后面的工作。
自定义工作队列有什么优缺点呢?
需要自己创建,系统开销大。优点是不会受到其他工作的影响。(因为这个流水线就是专门加工这一种零件的。)
二、工作队列相关API
尽管工作队列的实现机制非常复杂,但是我们使用工作队列其实就是在这个流水线上添加自己的物料,然后等待执行即可。
一个具体的工作(类比就是流水线上的物料)我们使用结构体 work_struct来描述的,我们使用工作队列的第一步就是先定义个工作队列。
文件位置路径:include/linux/workqueue.h
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};在这个结构体里面我们只需要关注func这个成员就可以了,他是一个函数指针,因为我们要把我们需要完成的工作写在这个函数里面。
<1>DECLARE_WORK宏
作用:动态定义并且初始化工作队列,用此方法之后无需再单独定义工作队列和使用INIT_WORK宏进行工作队列的初始化
函数原型:
文件位置路径:include/linux/workqueue.h
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
//参数:
//n:工作队列结构体名称
//f:工作函数<2>INIT_WORK宏
作用:动态初始化工作队列
函数原型:
文件位置路径:include/linux/workqueue.h
#define INIT_WORK(_work, _func) \
__INIT_WORK((_work), (_func), 0)
//参数:
//work:工作队列地址
//func:工作函数举例:
struct work_struct test;
在模块初始化函数中:
INIT_WORK(&test, func);
以上两句命令相当于
DECLARE_WORK(test, func) <3>schedule_work函数
作用:调度工作,把work_struct挂到CPU相关的工作结构队列链表上,等待工作者线程处理。
函数原型:
文件位置路径:include/linux/workqueue.h
static inline bool schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
//参数:
//work:工作队列地址需要注意的是,如果调度完工作,并不会马上执行,只是加到了共享的工作队列里面去,等轮到他才会执行。
如果我们多次调用相同的任务,假如上一次的任务还没有处理完成,那么多次调度相同的任务是无效的