tcpdump使用示例
前言介绍:
tcpdump - dump traffic on a network(转储网络上的流量)
tcpdump是一个用于截取网络分组,并输出分组内容的工具。凭借强大的功能和灵活的截取策略,使其成为类UNIX系统下用于网络分析和问题排查的首选工具
tcpdump 支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息
命令格式:
1 | NAME |
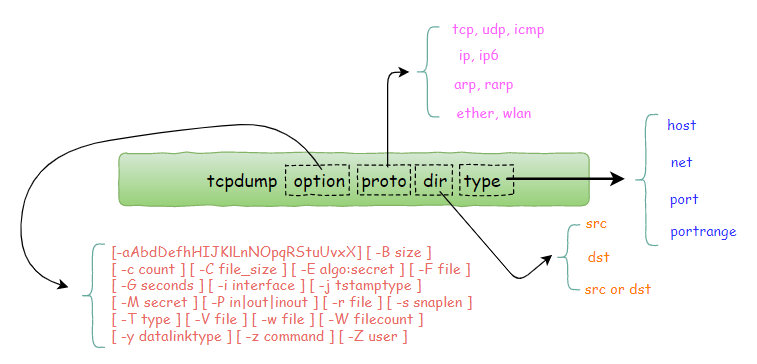
常用选项参数归纳:
下面的内容将介绍tcpdump命令的四个字段的常用选项。
option字段常用选项:
抓包选项:
-c:指定要抓取的包数量。
-i interface:指定tcpdump需要监听的接口。默认会抓取第一个网络接口
-n:对地址以数字方式显式,否则显式为主机名,也就是说-n选项不做主机名解析。
-nn:除了-n的作用外,还把端口显示为数值,否则显示端口服务名。
-P:指定要抓取的包是流入还是流出的包。可以给定的值为”in”、”out”和”inout”,默认为”inout”。
-s len:设置tcpdump的数据包抓取长度为len,如果不设置默认将会是65535字节。对于要抓取的数据包较大时,长度设置不够可能会产生包截断,若出现包截断,
:输出行中会出现”[|proto]”的标志(proto实际会显示为协议名)。但是抓取len越长,包的处理时间越长,并且会减少tcpdump可缓存的数据包的数量,
:从而会导致数据包的丢失,所以在能抓取我们想要的包的前提下,抓取长度越小越好。
输出选项:
-e:输出的每行中都将包括数据链路层头部信息,例如源MAC和目标MAC。
-q:快速打印输出。即打印很少的协议相关信息,从而输出行都比较简短。
-X:输出包的头部数据,会以16进制和ASCII两种方式同时输出。
-XX:输出包的头部数据,会以16进制和ASCII两种方式同时输出,更详细。
-v:当分析和打印的时候,产生详细的输出。
-vv:产生比-v更详细的输出。
-vvv:产生比-vv更详细的输出。
其他功能性选项:
-D:列出可用于抓包的接口。将会列出接口的数值编号和接口名,它们都可以用于”-i”后。
-F:从文件中读取抓包的表达式。若使用该选项,则命令行中给定的其他表达式都将失效。
-w:将抓包数据输出到文件中而不是标准输出。可以同时配合”-G
time”选项使得输出文件每time秒就自动切换到另一个文件。可通过”-r”选项载入这些文件以进行分析和打印。
-r:从给定的数据包文件中读取数据。使用”-“表示从标准输入中读取。
proto 字段常用选项:
根据协议进行过滤,可识别的关键词有: tcp, udp, icmp, ip, ip6, arp, rarp,ether,wlan, fddi, tr, decnet
缺省值是监听所有协议的信息包。
direction 字段常用选项:
用来修饰参数id的方向,即是发送端还是接收端。可识别的关键字有:src, dst,同时你可以使用逻辑运算符进行组合,比如 src or dst
- dst,接收端
- src,发送端
- src && dst,发送端并且是接收端
- src || dst,发送端或者是接收端。也是缺省值
type 字段常用选项:
用来描述参数id的类型。
可识别的关键词有:host, net, port, portrange,这些词后边需要再接参数。
- host(缺省类型): 指明一台主机,如:host 210.27.48.2
- net: 指明一个网络地址,如:net 202.0.0.0
- port: 指明端口号,如:port 23
- portrange:指明一个端口范围,如:portrange 6000-6008
理解 tcpdump 的输出:
tcpdump 输出的内容虽然多,却很规律。
这里以我随便抓取的一个 tcp 包为例来看一下
1 | 21:26:49.013621 IP 172.20.20.1.15605 > 172.20.20.2.5920: Flags [P.], seq 49:97, ack 106048, win 4723, length 48 |
从上面的输出来看,可以总结出:
1 | 第一列:时分秒毫秒 21:26:49.013621 |
Flags 标识符
1 | [S]: SYN(开始连接) |
使用示例:
基于IP地址过滤:host
指定 host ip 进行过滤
1 | $ tcpdump host 192.168.10.100 |
数据包的 ip 可以再细分为源ip和目标ip两种
1 | # 根据源ip进行过滤 |
基于网段进行过滤:net
若你的ip范围是一个网段,可以直接这样指定
1 | $ tcpdump net 192.168.10.0/24 |
网段同样可以再细分为源网段和目标网段
1 | # 根据源网段进行过滤 |
基于端口进行过滤:port
使用port就可以指定特定端口进行过滤
1 | $ tcpdump port 8088 |
端口同样可以再细分为源端口,目标端口
1 | # 根据源端口进行过滤 |
如果你想要同时指定两个端口你可以这样写
1 | $ tcpdump port 80 or port 8088 |
但也可以简写成这样
1 | $ tcpdump port 80 or 8088 |
如果你的想抓取的不再是一两个端口,而是一个范围,一个一个指定就非常麻烦了,此时你可以这样指定一个端口段。
1 | $ tcpdump portrange 8000-8080 |
对于一些常见协议的默认端口,我们还可以直接使用协议名,而不用具体的端口号
比如 http == 80,https == 443 等
1 | $ tcpdump tcp port http |
基于协议进行过滤:proto
常见的网络协议有:tcp, udp, icmp, http, ip,ipv6 等
若你只想查看 icmp 的包,可以直接这样写
1 | $ tcpdump icmp |
protocol 可选值:ip, ip6, arp, rarp, atalk, aarp, decnet, sca, lat, mopdl, moprc, iso, stp, ipx, or netbeui
基本IP协议的版本进行过滤
当你想查看 tcp 的包,你也许会这样子写
1 | $ tcpdump tcp |
这样子写也没问题,就是不够精准,为什么这么说呢?
ip 根据版本的不同,可以再细分为 IPv4 和 IPv6 两种,如果你只指定了 tcp,这两种其实都会包含在内。
那有什么办法,能够将 IPv4 和 IPv6 区分开来呢?
很简单,如果是 IPv4 的 tcp 包 ,就这样写(友情提示:数字 6 表示的是 tcp 在ip报文中的编号。)
1 | $ tcpdump 'ip proto tcp' |
而如果是 IPv6 的 tcp 包 ,就这样写
1 | $ tcpdump 'ip6 proto tcp' |
关于上面这几个命令示例,有两点需要注意:
- 跟在 proto 和 protochain 后面的如果是 tcp, udp, icmp ,那么过滤器需要用引号包含,这是因为 tcp,udp, icmp 是 tcpdump 的关键字。
- 跟在ip 和 ip6 关键字后面的 proto 和 protochain 是两个新面孔,看起来用法类似,它们是否等价,又有什么区别呢?
关于第二点,网络上没有找到很具体的答案,我只能通过man tcpdump的提示, 给出自己的个人猜测,但不保证正确。
proto 后面跟的<protocol>的关键词是固定的,只能是 ip, ip6, arp, rarp, atalk, aarp, decnet, sca, lat, mopdl, moprc, iso, stp, ipx, or netbeui 这里面的其中一个。
而 protochain 后面跟的 protocol 要求就没有那么严格,它可以是任意词,只要 tcpdump 的 IP 报文头部里的 protocol 字段为<protocol>就能匹配上。
理论上来讲,下面两种写法效果是一样的
1 | $ tcpdump 'ip && tcp' |
同样的,这两种写法也是一样的
1 | $ tcpdump 'ip6 && tcp' |
基于包大小进行过滤
若你想查看指定大小的数据包,也是可以的
1 | $ tcpdump less 32 |
根据 mac 地址进行过滤
例子如下,其中 ehost 是记录在 /etc/ethers 里的 name
1 | $ tcpdump ether host [ehost] |
过滤通过指定网关的数据包
1 | $ tcpdump gateway [host] |
过滤广播/多播数据包
1 | $ tcpdump ether broadcast |
一些组合用法示例:
tcpdump ether src 01:58:00:00:00:00 -i eth0 -vv
附录:tcpdump的参数大全
1 | -A 以ASCII码方式显示每一个数据包(不会显示数据包中链路层头部信息). 在抓取包含网页数据的数据包时, 可方便查看数据(nt: 即Handy for capturing web pages). |
参考文章:
http://www.360doc.com/content/22/0617/15/65840031_1036400463.shtml
https://blog.csdn.net/qq_40309341/article/details/119026295